SpecInfer: Accelerating Generative LLM Serving with Speculative Inference and Token Tree Verification
What is SpecInfer
The high computational and memory requirements of generative large language models (LLMs) make it challenging to serve them quickly and cheaply. SpecInfer is an open-source distributed multi-GPU system that accelerates generative LLM inference with speculative inference and token tree verification.
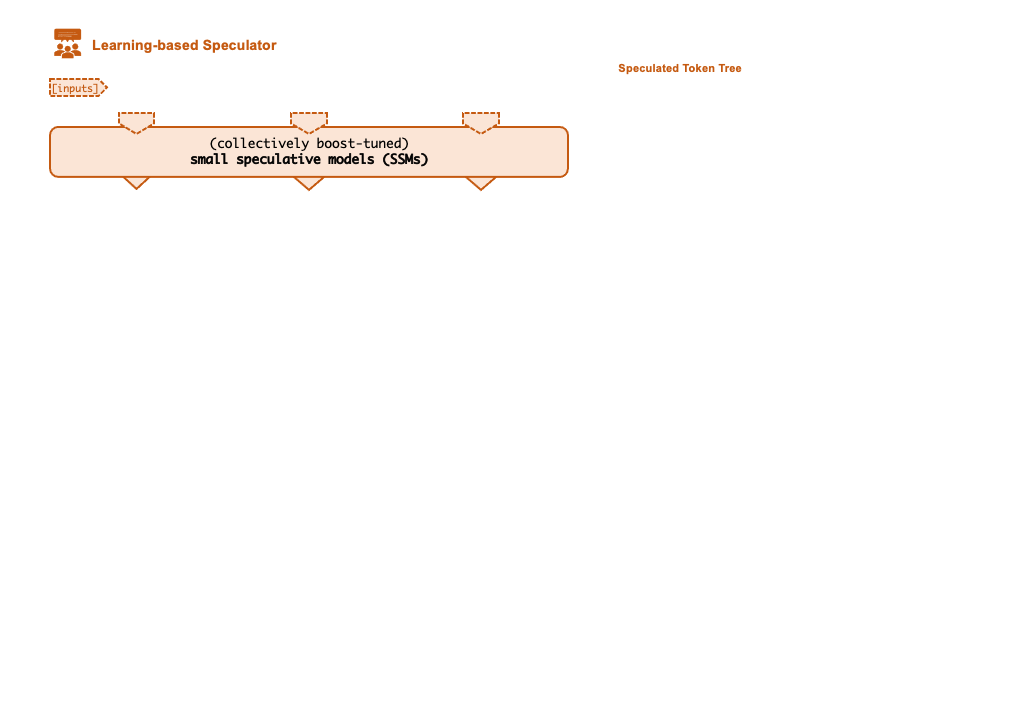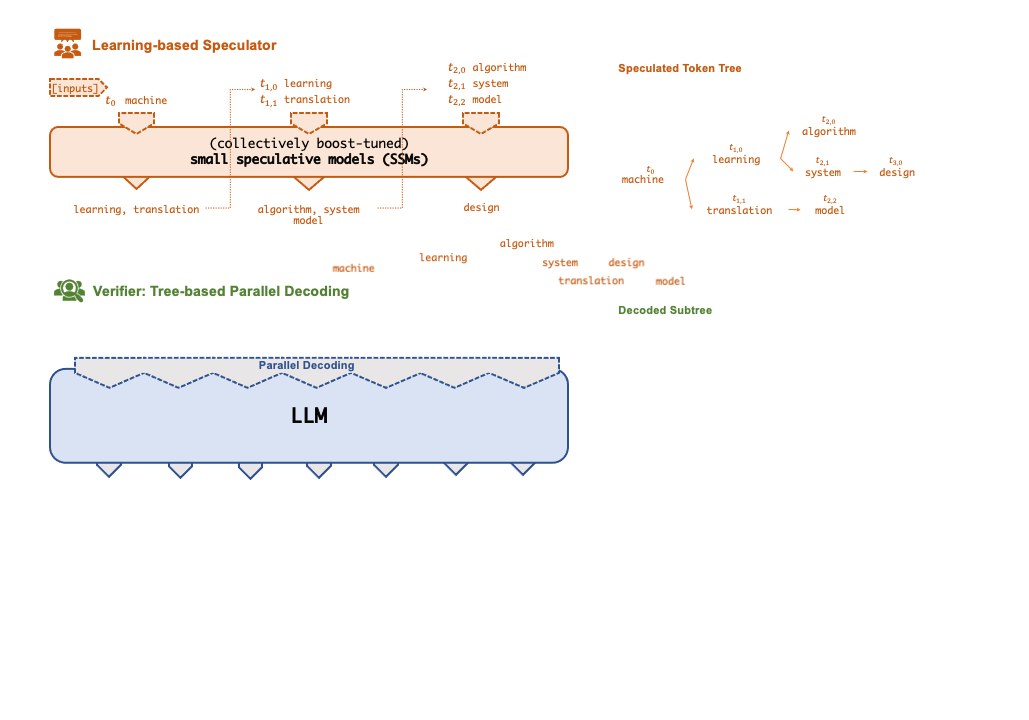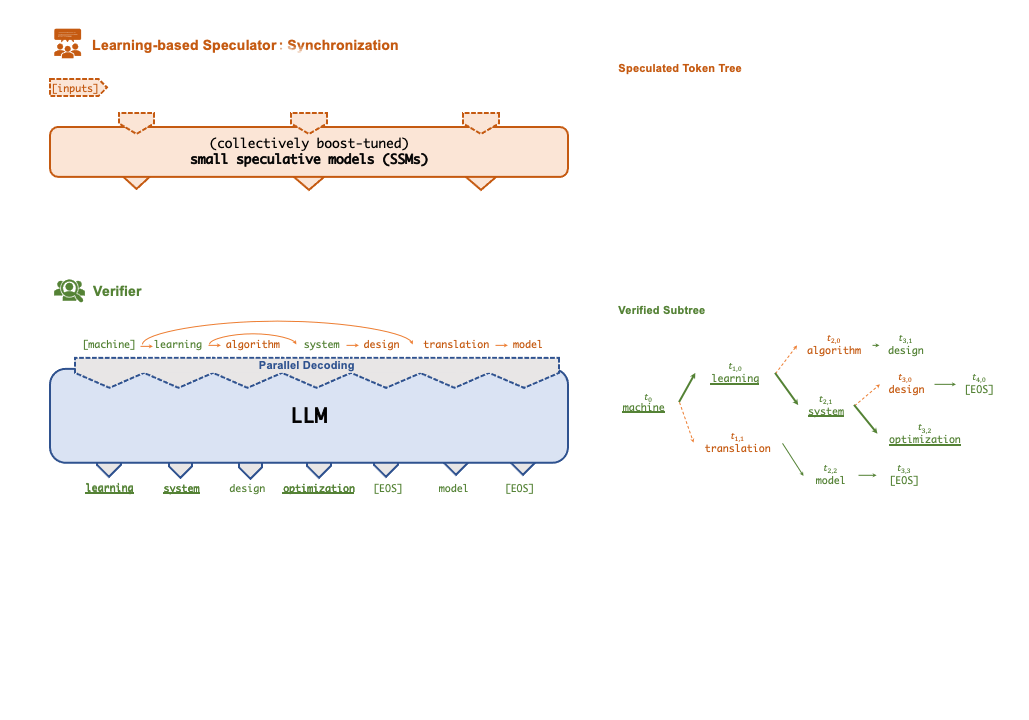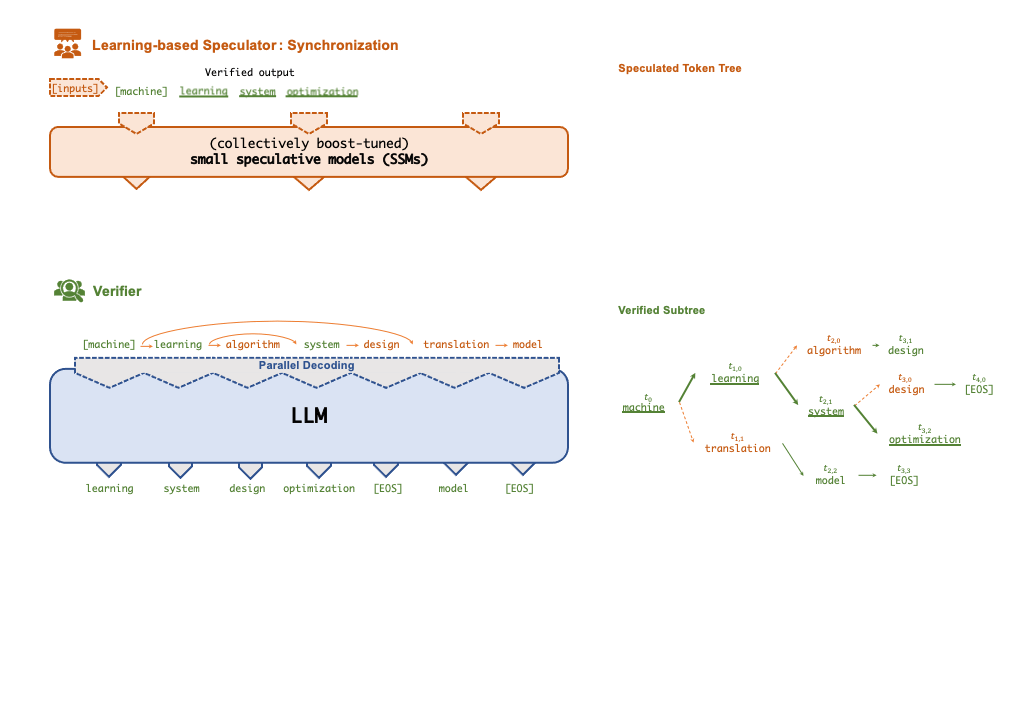
A key insight behind SpecInfer is to combine various collectively boost-tuned small speculative models (SSMs) to jointly predict the LLM’s outputs; the predictions are organized as a token tree, whose nodes each represent a candidate token sequence. The correctness of all candidate token sequences represented by a token tree is verified against the LLM’s output in parallel using a novel tree-based parallel decoding mechanism.
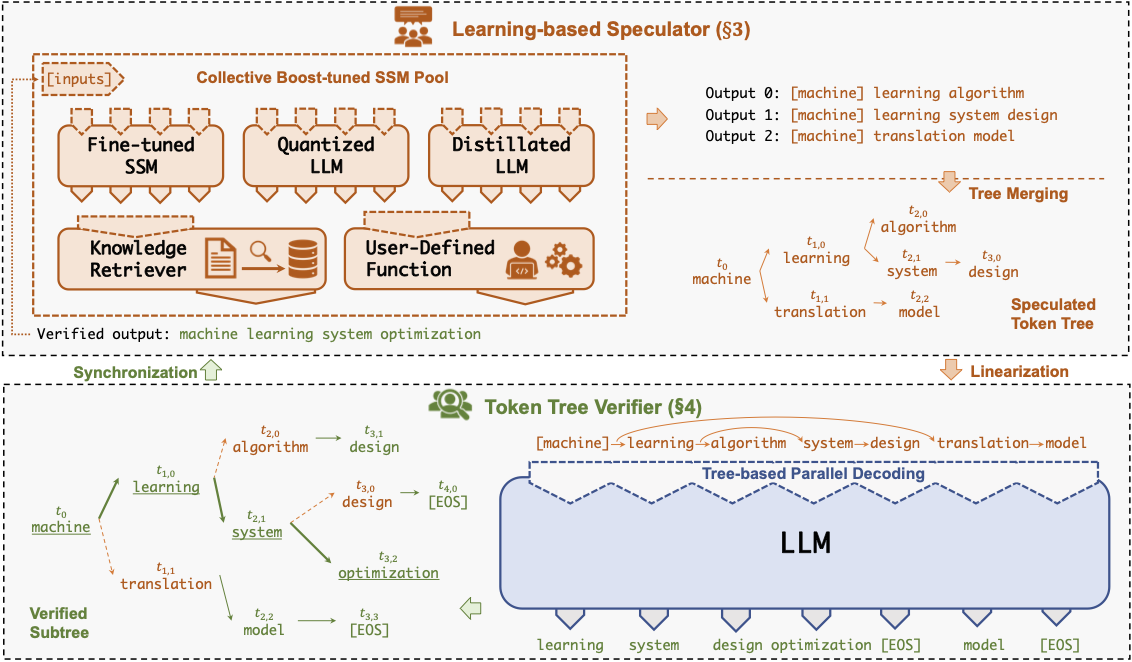
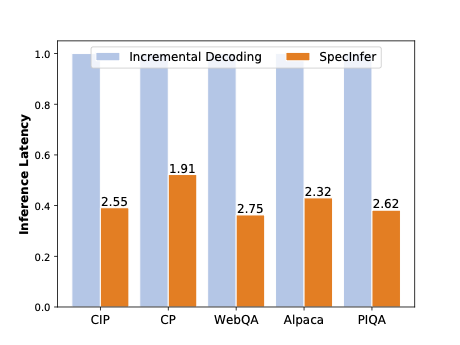
SpecInfer uses an LLM as a token tree verifier instead of an incremental decoder, which largely reduces the end-to-end inference latency and computational requirement for serving generative LLMs while provably preserving model quality.
Build/Install SpecInfer
SpecInfer is built on top of FlexFlow. You can build/install SpecInfer by building the inference branch of FlexFlow. Please read the instructions for building/installing FlexFlow from source code. If you would like to quickly try SpecInfer, we also provide pre-built Docker packages (flexflow-cuda with a CUDA backend, flexflow-hip_rocm with a HIP-ROCM backend) with all dependencies pre-installed (N.B.: currently, the CUDA pre-built containers are only fully compatible with host machines that have CUDA 11.7 installed), together with Dockerfiles if you wish to build the containers manually.
Run SpecInfer
The source code of the SpecInfer pipeline is available at this GitHub folder. The SpecInfer executable will be available at /build_dir/inference/spec_infer/spec_infer at compilation.
You may refer to our GitHub page for details on examples, tokenizers support, mixed-precision support and more.
Paper
This project is initiated by members from CMU, Stanford, and UCSD. We will be continuing developing and supporting SpecInfer and the underlying FlexFlow runtime system. The following paper describes design, implementation, and key optimizations of SpecInfer.
- Xupeng Miao*, Gabriele Oliaro*, Zhihao Zhang*, Xinhao Cheng, Zeyu Wang, Rae Ying Yee Wong, Zhuoming Chen, Daiyaan Arfeen, Reyna Abhyankar, and Zhihao Jia. SpecInfer: Accelerating Generative LLM Serving with Speculative Inference and Token Tree Verification.